Remove duplicate values in an Array
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Products and Environment
This section reflects the products and operating system used to create the example.To download NI software, including the products shown below, visit ni.com/downloads.
- LabVIEW
Software
Code and Documents
Attachment
Overview
This example shows one method for how to remove duplicate elements from an array.
Description
The attached code has been implemented for Double, U32, String, Path, and Variant data types. If you are dealing with large amounts of data or are concerned about execution speed, you may add another instance to the polymorphic VI. This algorithm requires the use of the array sort function. The variant data type does not support sort, so the array is converted into a string array, then sorted, and converted back into a variant array.
If you would like a more permanent solution please check out Open G's free and open source solution to this problem. Note Open G is not supported by NI, but they have a very active developer community.
Requirements
LabVIEW 2012 (or compatible)
Steps to Implement or Execute Code
- Download attached zip folder " Remove Duplicate Elements from Array_LV2012_NI Verified"
- Open the project and launch the main VI
- Enter the string array values
- Run the VI
- Check different instances of the polymorphic VI
Additional Information or References
Block Diagram for the String Instance


Front Panel of Main VI

**This document has been updated to meet the current required format for the NI Code Exchange.**
Example code from the Example Code Exchange in the NI Community is licensed with the MIT license.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
There is also the OpenG tool for removing duplicate elements from an array. The OpenG version is polymorphic, and adapts to your input type.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
There is a small error with this. If you supply an empty array it returns an array with a single element.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Fixed, I also found another bug that is caused when an array is indexed past its last value, If you gave my previous version an input of [1,0,1] It would return [1] because when you ask for the value in an index greater than the number of integers in the array, for a numeric array the value will be zero rather than null, and for a boolean it will be false...etc. I also modified the VI to natively accept any array that labview can handle. Let me know if you see bugs, and thanks for the catch.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
There are quite a few bugs, for example:
- If the input array contains a single NaN, the output will be twice the size with two NaNs.
- Why do you make the VIs reentrant? That does not seem necessary.
You should not claim that it can accept any array, because that's not true. It only accepts most simple arrays. It does not accept e.g. arrays of complicated clusters, for example.
There is a lot of unnecessary code:
- The T/F diagram constants in the upper case structure are not needed. You can get the same result by branching from the wire going to the case selector. It does not need to enter the case structure.
- It seems more reasonable to have an diagram constant as empty array instead of an empty control.
- To get element zero you don't need to wire the index of index array.
- Use reasonable names for controls and indicators, not "array 3" or "array".
- Add comments to the code.
- The inner "array size" belongs outside the while loop, because the size cannot change during the while loop. This operation needs to be done only once per iteration of the FOR loop and not repeated with every iteration of the while loop. (The compiler will still fold it for you so it actually makes no difference, but still, it's cleaner to place it in the correct spot)
- The FP and diagram contains way too much whitespace. Why are they 2 screens wide? Make the sizes manageable?
- If you index on the FOR loop, you don't need to wire N
- Rattling through 2 stacked loops in inefficient. Something similar to the openG version is probably 10x faster.
- All you need is one FOR loop and one case structure. Things can be done "in place".
As a simple example, I have rewritten the DBL version here (not fully debugged). Modify as needed.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
altenbach - that's inspired!
- Re-using the same memory space allocated by the input array to prevent data duplication and unecessary memory allocations
- Using reshape to truncate the resultant array - I presume this is more (memory) efficient than Delete From Array?
Out of interest, when was conditional break introduced in for loop and how far back can this subvi be reverted?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thoric,
The conditional terminal is relatively recent. I think it got introduced in LabVIEW 8.5. If you omit it here, duplicate NaNs will not be removed and that might be OK. This part of the code needs to be changed anyway for other datatypes.
No, "reshape", "delete from array" and "array subset" are all very similar in performace and any of them can be used here. I personally prefer "reshape" because it does not have any unecessary terminals and is thus cleaner. 
(Note that in older documentation for "reshape", it was claimed that it operates "in place". This is incorrect and has been edited from the newer help pages. You can easily test by showing buffer allocations.)
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Some suggestions to modify the above UniqueArray_01022013.zip:
1. (Assuming you're on LV 2012 or above) UniqueArrayPath should use the <Not A Path> constant as the input to initialize the shift register so that if an empty path is included in the array of inputs, it will be one of the final outputs. Also, a bit of code checking the first element should be added in case the array is only one element of <Not A Path> so that the final array is not empty.
2. The U32 input should be cast to I64 (and back to U32 at the end) to avoid coercion dots since NaN isn't part of the set of U32 in LabVIEW. The shift register can then be initialized at -1 (I64) and no loss of data should occur for U32 data.
3. I see no particular reason the empty string should be excluded from the resultant unique string array. Similar code as #1 above can be added to check for the empty string as the first element and include it should it be found to be part of the original array.
4. I have a hard time with the variant version of this code. I think we need to be very specific about the use case in which this VI is valid. If you create an array of 4 variants, each converted to variant separately, of 0, "A", 1, "B" and input that to the VI (called as a sub), you will get a "Memory or data structure corrupt." error in LabVIEW. This VI will only work generally for a set of data which has the same type to begin with, or else we risk the reassignment of type data when the variant is reconstructed getting re-ordered or padded as not all types use the same number of elements in the type array output of the Variant To Flattened String(as is the case here). This code could be strengthened using clusters or other, but even at that, it begs the question about uniqueness with variants. Is "0" the same as 0? Those types of decisions about the meaning of "unique" should be made on an implementation specific basis, I suppose.
I'll attached my updated version of the code and appreciate any feedback.
Not my tempo... AGAIN!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
So I've done some bench testing in order to compare various methods. I would categorize them as follows (all tested using both highly self-similar array with only a few unique elements, and tested with arrays containing a large number of unique elements):
1. Sort, then single loop through the array.
2. Nested loops.
3. Using a variant's attributes to attempt to create a hash table in LabVIEW.
Of the three methods, I've found the following:
1. Sort, then single loop appears to perform the best across the board from highly self similar arrays to arrays that contain all unique elements.
2. Nested loops can actually beat the processing time of sort first methodologies for some arrays, but for others, it's horrible. Given the disparity, this method seems less desirable if the input array doesn't have a known structure a priori.
3. This is the most effiencient method in some other environments (see: http://stackoverflow.com/questions/3350641/array-remove-duplicate-elements ). But in LabVIEW, there's a great cost in time to generating a hash-like structure using variant attributes one at a time when you have a huge array. The lookups are efficient, but the time to generate is expensive. In the long run, it ends up costing more in real time to do things this way in LabVIEW.
Not my tempo... AGAIN!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Seems to me that the proposed version is quite too mich complicate. I use this code in my program and works quite well.....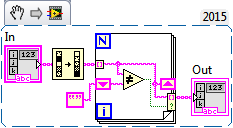
For sorting complexity should be O(N Log N) if quick sort is used and the other loop introduce only a factor N. If a double loop with comparison is used then complexity should be of order N^2.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
To be fair, the conditional autoindexing functionality did not exist in LabVIEW at the time this code was released. And in its first release (LabVIEW 2012) the conditional autoindexing was quite inefficient as well. Since then it has been optimized though, so there is not much that beats it now...
Both the original and the code suggested by Guiseppe will reorder the array, so if there is any value in the original order (disregarding the duplicates) you need to do it differently. The OpenG Remove Duplicates-function for example will retain that (but could also be optimized).
