- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
I have taken the OOP Plunge...but have a couple of questions
Solved!03-16-2012 12:04 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I am diving into LVOOP and I'm familiar with OOP in general, as I have coded in c++ on some large projects at my previous company. I have also used some LVOOP before, but it was more basic than the Actor Framework. However, as I am reusing code, I keep thinking this would be much easier to modify for all this new hardware if I had used OOP in the first place. Thus, I have decided to dive into the actor framework.
I am going to start by rewriting a fairly sizeable RT application, but have a couple of questions about architecture. Currently, I have 5 loops (TCP/IP, Acquisition, processing, logging, monitor folder for new files FTP'd). I will list my thoughts as to the architecture to use with the actor framework, so please give me any feedback as deemed necessary.
I would like to have TCP/IP, acquisition , logging, and monitor folder loops all be actors, and the processing will be the message handler of the acquisition loop. OOP will be great for this because I have many different data types from the acquisition, so each type can have a message that is sent to the TCP's Do.vi to handle the sending of the data. I can have a similar architecture for the logging (different do.vi to write to the TDMS file for each message class, of which private data will be a particular data type (waveform, 2d double array etc).
I do have a question about the inter-process communication though. I thought about having the TCP actor be launched by the processing actor since data will go from acquisition->processing->TCP and logging, but the loops TCP and logging need to handshake with the data acquisition. Different commands can be sent from the host to the RT which then need to be given to the acquisition thread. Because the processing loop will have a reference to the queue to the acquisition, is it "kosher" to this queues reference to the TCP loop? Or should I send from TCP -> Process -> acquisition (i.e. have process play middle man so I'm not passing queue references around, other than the message queue pair)?
Please let me know if you need more information, or for me to clarify anything. Because I have had SM, QSM, and PDQSM drilled into my brain, it's very hard to think outside of those architectures. I think basically I am trying to figure out when to have a nested actor and when not to, along with if I have nested actors and data needs to get back to the caller of the caller, what is the best way to do this. Also, any architecture changes or suggestions are always appreciated.
On a side note, I have one more question. How come if I wire a message that inherits from class "message" into the priority queue VI there is no coercion dot, but there is if I create a generic message indicator? (see attachment)
Solved! Go to Solution.
{kind=link}
03-17-2012 10:31 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I had a thought on this but tell me if I'm way off base. I could have one actor launch the others. This way that top level actor would have two way communication with the other actors. When the actors needed to communicate between each other, they could pass their message to the top level actor who could then distribute the messages to the correct actors accordingly
03-18-2012 12:45 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
[Disclaimer: These comments reflect my personal opinions. While I haven't used the AF directly, I do follow many of the principles encouraged by it and believe actor-oriented design is the next step in building sustainable LV applications.]
I thought about having the TCP actor be launched by the processing actor since data will go from acquisition->processing->TCP and logging, but the loops TCP and logging need to handshake with the data acquisition.
This is what I call "Designing by Flow Chart." Flow charts are a useful tool for figuring out processes, but IMO they are not a good foundation for software design. It's impossible for a flow chart to capture even a significant subset of possible execution paths in a modern event-based program. Furthermore, flow charts don't address one of the most important aspects of application design--managing dependencies. Designing by flow chart works fine for single-threaded polling environments, such as simple C desktop apps or code for inexpensive microcontrollers. It is completely out of place in LV's parallel environment.
I think basically I am trying to figure out when to have a nested actor and when not to, along with if I have nested actors and data needs to get back to the caller of the caller, what is the best way to do this.
Nesting is a form of encapsulation. It's used to hide internal complexity from other parts of the program (and other programmers) that don't need to worry about it. It is appropriate when the nesting actor needs to use the nested actor to fulfill its responsibilities. If that's not the case then establishing that nest will probably create more problems for you than it solves. So my question to you, is the functionality exposed by the TCP actor required for the Processing actor to fulfill its responsibilities? (Based on the names you've chosen, I'd guess no.)
I had a thought on this but tell me if I'm way off base. I could have one actor launch the others. This way that top level actor would have two way communication with the other actors. When the actors needed to communicate between each other, they could pass their message to the top level actor who could then distribute the messages to the correct actors accordingly.
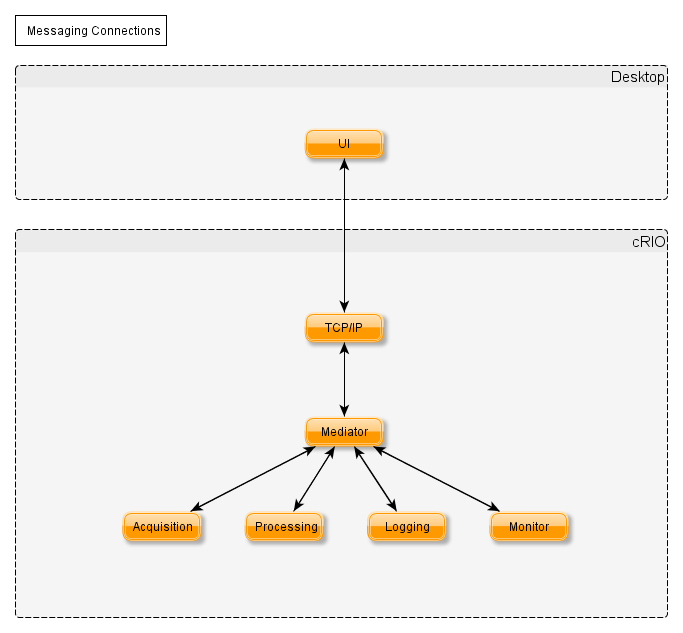
Nope, you're not way off base. This is "hierarchical messaging" (HM) and I do it all the time. It promotes reuse and testability by limiting the dependencies between various actors.** In the diagram below, all the cRIO actors except the Mediator can (if you take care in your coding) be copied and used in other projects as is. I also think it is much, much easier to look at the code and understand what is happening when HM is used compared to observer based messaging where each actor sends messages directly to the destination actor.
Of course there are tradeoffs. For example, in HM when a message has to be delivered across a large messaging tree, each actor along the way has to repackage the message for the next actor in the line. It's not difficult, but it can be tedious.
**[My understanding of the early versions of the AF was all messages were "input" messages. That is, in order to send a message to another actor you had to call a Msg.Send method written specifically for that actor. In the HM system below, the Acquisition actor will have the Mediator message's custom Send methods in its source code, making Acquisition statically dependent on Mediator. Obviously this limits our ability to easily reuse the Acquisition actor. One way to break that dependency is for the Acquisition actor needs to have self-defined "output" messages which Mediator will catch and process according to you application's specific requirements. I believe the current AF version has a way to break that two-way dependency, but I haven't worked with it enough to tell you how to do it. Hopefully somebody else will chip in.]
03-18-2012 01:03 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I believe the current AF version has a way to break that two-way dependency, but I haven't worked with it enough to tell you how to do it. Hopefully somebody else will chip in.
Check page 6 of the document "Using the Actor Framework" found here. Look under "Zero Coupling Solution."
03-19-2012 11:07 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Nope, you're not way off base. This is "hierarchical messaging" (HM) and I do it all the time. It promotes reuse and testability by limiting the dependencies between various actors.** In the diagram below, all the cRIO actors except the Mediator can (if you take care in your coding) be copied and used in other projects as is.
**[My understanding of the early versions of the AF was all messages were "input" messages. That is, in order to send a message to another actor you had to call a Msg.Send method written specifically for that actor. In the HM system below, the Acquisition actor will have the Mediator message's custom Send methods in its source code, making Acquisition statically dependent on Mediator. Obviously this limits our ability to easily reuse the Acquisition actor. One way to break that dependency is for the Acquisition actor needs to have self-defined "output" messages which Mediator will catch and process according to you application's specific requirements. I believe the current AF version has a way to break that two-way dependency, but I haven't worked with it enough to tell you how to do it. Hopefully somebody else will chip in.]
Thank's for your excellent response. I do have a couple of questions about the paragraphs above though. I understand the benefits of making sure there is zero coupling between the all threads and the mediator, but don't fully understand, from the pdf, the best way to pass the messages the mediator will be expecting to callee, and tie them to a specific event that the callee may have happen. I also am a bit confused on how to architect code in a way that would allow for it to be completely copied and reused. For instance, in my acquisition loop I may have DAQ tasks of 4 different types or 8 different types if the PXI chassis has a different configuration and those are initialized depending on what channels the user selects on the PC from a config screen. Is the best way to handle this to have the DAQ loop task initialization be handled by the "mediator" sending messages stating which tasks to init, this way the DAQ loop can be totally independant of the mediator? Also, what about the case where in one app you use waveform data, and another you need 2d double array data etc from the DAQ task. It seems to me it will be impossible to avoid changing the private data in this case and a true copy-paste would not be possible. Your thoughts?
03-19-2012 01:58 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I understand the benefits of making sure there is zero coupling between the all threads and the mediator
I think "zero coupling" is a misnomer. Two components are "coupled" when a change in one necessitates a change in the other. That includes things like data schemas and inheritance hierarchies. Any two components in direct communication are going to be coupled to some extent. The "no coupling" solution is better described as a "one way static dependency" solution, where the caller contains callee-specific code but the callee does not contain any code associated with the caller. (The text alludes to that, but the title is a bit misleading.)
Zero coupling between the mediator and working threads is possible, but it will be a lot more work and add a lot of complexity to your app. Plus there's little value in doing so--the mediator is a managing messages and actions of subordinate actors. It has to know stuff about the actors its managing. Unless you have a specific need for a generalized mediator, I think it's better to focus on ensuring a one-way dependency and allow the mediator to be application-specific code.
but don't fully understand, from the pdf, the best way to pass the messages the mediator will be expecting to callee, and tie them to a specific event that the callee may have happen.
The best way is highly situation dependent. A superb technical solution that takes you six months to implement is worthless if your project needs to be done in 3 weeks. The pdf describes one way to accomplish that goal.
We'll call your callee actor LoggingActor. In principle the actor accepts requests to do some action from the caller. These requests could be things like AppendData, SetPath, or FlushToDisk. You also want the actor to announce when interesting events happens internally. (I'm using "events" as a common term, not as a programming construct.) Perhaps we decide it needs to announce DataSavedToFile to report a successful save operation and FilePermissionError to report an unsuccessful save. The requests are input messages and the events are output messages.
In the AF all messages are written for a specific actor. Input messages are statically dependent on the actor for which they are written. The high coupling solution in the pdf is the fastest way to write code, but it also treats all messages as an input message. The events we've identified as belonging to LoggingActor are implemented as input messages to the mediator. Invoking those messages in LoggingActor puts mediator-specific code in LoggingActor, thereby creating a two-way static dependency between the mediator and LoggingActor.
To implement output messages in the AF, create message classes for LoggingActor's output messages along with the Send and Do methods. Those classes and methods will be abstract--there's no code on the block diagram. Place a class constant for each output message in LoggingActor's private data. With your mediator actor create child classes of each of the output messages (I'll call them LoggerSavedFile and LoggerFilePermissionError.) and override the methods, putting the specific implementation in place.
(Now we're finally getting to your question...)
Create one LoggingActor input message for each output message. In this example the input messages will be Set DataSavedToFileMsg and Set FilePermissionErrorMsg. The message data is a DataSavedToFile object and FilePermissionError object, respectively. When LoggingActor processes those messages, it stores the objects in its private data. To trigger those messages to be sent to the mediator, place DataSavedToFile.Send and FilePermissionError.Send (the abstract classes, not the child classes) on the LoggingActor's block diagram in the same place you would with the high coupling solution.
In your setup code, after the mediator starts up LoggingActor you'll need to use the Set DataSavedToFileMsg to send a LoggerSavedFile object and Set FilePermissionErrorMsg messages to send a LoggerFilePermissionError object to that instance of LoggingActor. When LoggingActor gets to the point on the block diagram where you placed the abstract DataSavedToFile.Send, your child class methods containing the actual implementation will be called because the run-time object is a child class, not a parent class.
It's all very confusing when I type it out in text, but it's really not that bad.
I also am a bit confused on how to architect code in a way that would allow for it to be completely copied and reused. For instance, in my acquisition loop...
My advice... don't try to design a reusable component up front. Let them evolve into being. Whenever I've tried to design something reusable I inevitably get it wrong, and then I have to deal with the monster headaches of supporting an inadequate design.
What I do instead now when I identify functionality that may be reusable is make it "reasonably" portable. I make sure it has no dependencies on other components and I give it input and output messages according to the functionality I need in that project. When I work on another application that can benefit from that functionality, I copy and paste the entire component over to my new project, and add new input and output messages as needed. While making the modifications, I focus on making the component's api more general instead of just adapting from the previous project's specific needs to the current project's specific needs. After 3-4 iterations I usually have a pretty good idea of how the component will be used and the api has been refined enough make it easy to use. At that point I'm comfortable releasing it as a reusable component.
Regarding the acquisition loop, there are many ways to deal with that. I'd advise postponing that until you've been through the process a couple times and understand the tradeoffs associated with OO design better. Start with the logging and tcp actors.
Also, what about the case where in one app you use waveform data, and another you need 2d double array data etc from the DAQ task. It seems to me it will be impossible to avoid changing the private data in this case and a true copy-paste would not be possible. Your thoughts?
The easiest solution is to store all the data in a common format and let the mediator transform it from that format to the data type needed for that application. A better technical solution (but also more complicated) is to create DAQ classes for specific data types and use dependency injection when setting up the acquisition actor.
03-19-2012 02:13 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Daklu wrote:
I think "zero coupling" is a misnomer.......acquisition actor.
Very helpful. It will take me a bit of time to digest it, but thanks a bunch.
03-19-2012 02:46 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Just a note...
After rereading the pdf I believe "high coupling," "low coupling," and "zero coupling" are referring only to how much the callee is coupled to the caller. It's not saying anything about how coupled the caller is to the callee (or by extension, how coupled they are to each other.) In that respect I think the terminology is accurate.
03-20-2012 05:11 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Daklu wrote:
When LoggingActor gets to the point on the block diagram where you placed the abstract DataSavedToFile.Send, your child class methods containing the actual implementation will be called because the run-time object is a child class, not a parent class.
Will you explain this a little more?
Callee "LoggingActor" has a message class DataSavedToFile that is a child class of Message.
Caller has a message class CalleeActorReportsDataSavedToFile that is a child class of DataSavedToFile.
I don't see how the caller's Do.vi or Send.vi gets dynamically dispatched instead of the LoggingActor's abstract methods.
03-20-2012 05:25 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Part of what's confusing me is that the Using AF pdf says the child class of a Report type message has a Do.vi that is invoked by the callee actor. But in the Offline Demo, the Feedback Cooler callee doesn't use the abstract class method. Perhaps if the messages were grouped by actors in that demo, I could see the correlation better - perhaps not, though 
