Fast Base64 Encoder/Decoder using LabVIEW
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Products and Environment
This section reflects the products and operating system used to create the example.To download NI software, including the products shown below, visit ni.com/downloads.
- LabVIEW
Software
Code and Documents
Attachment
Overview
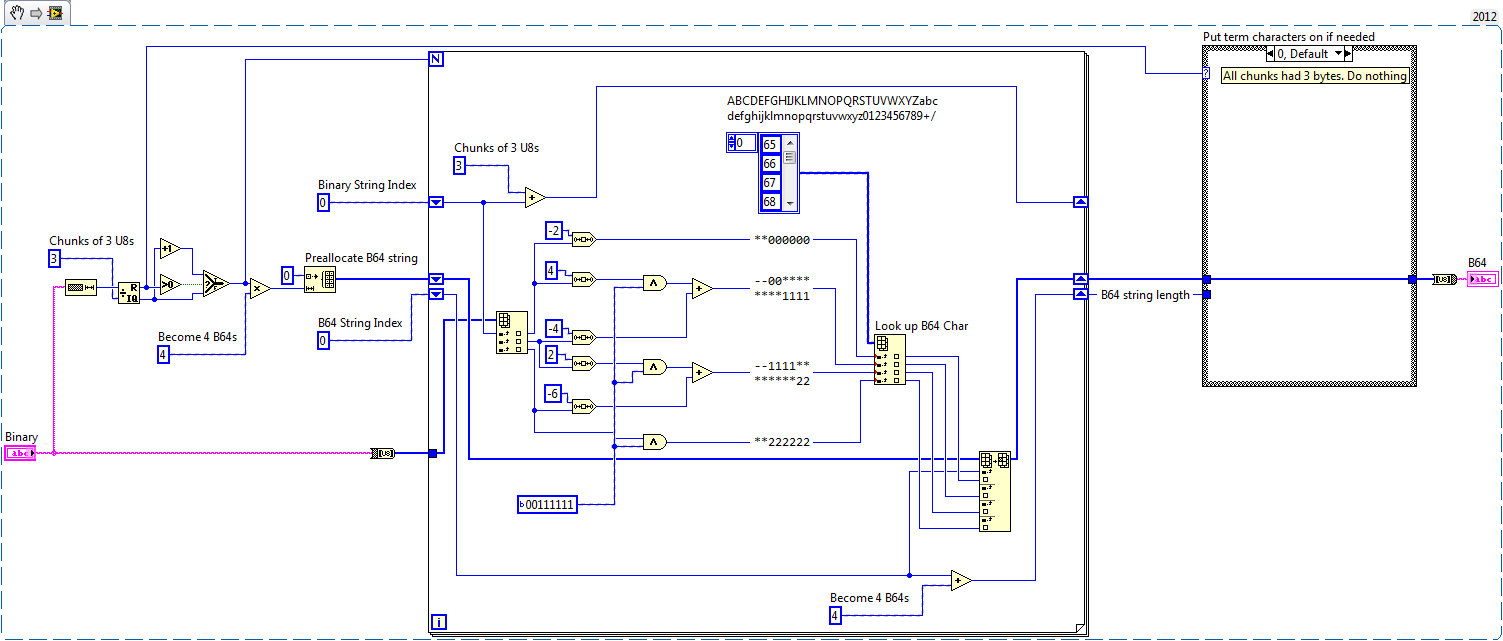
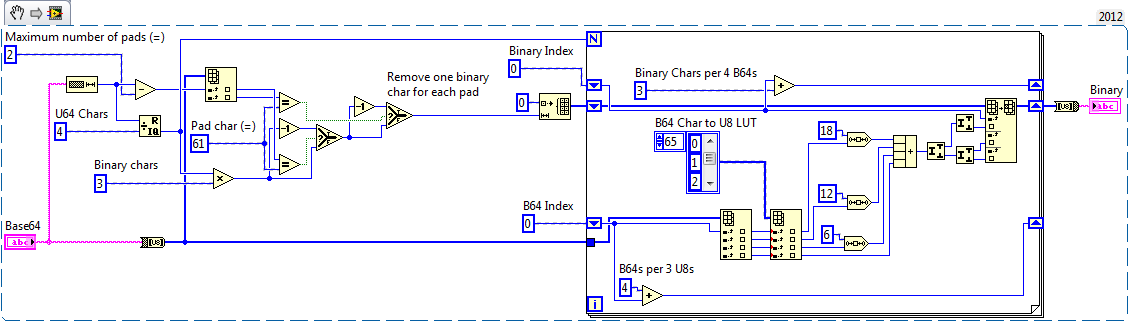
This VI shows how to encode and decode Base64.
Description
This example provides fast base64 encoder and decoder (for performance reasons in two separate files).
Attention: the decoder does no check on of the input data. Please remove any whitespaces (spaces, tabs, line breaks) and any "non-Base64" stuff from the input string before feeding to the base64 decoder (this is also for performance reasons, the user can decide If he is getting valid data only anyway or if it has to be sanitized first)
If you want to understand, how bas64 encoding/decoding works, please check other implementations. These VIs have been optimized for speed. And while trying to keep to LabView design rules, the implementation uses some optimizations that are not obvious on first glance.
If you need a really fast base64 encoder/decoder, that does not depend on any external code (like C-libraries) than this is for you. These VIs only use LabView standard functions and should run on any platform (even FPGA and embedded).
The VIs are configured to be inlined into the calling VI. This should reduce execution times. If you need to do debugging, just change the configuration of this vi (but do not forget to revert to the original state to get optimum performance).
There is still room for optimizations, so there might be further, faster versions in the future.
Licensing: Everyone is free to use these VIs under one of the following licenses (Just select the one that meets your needs the best)
- GNU GPL v2
- GNU GPL v3
- MIT License
- Creative Commons CC-by
Requirements
- LabVIEW Base Development System 2012 (or compatible)
Steps to Implement or Execute Code
- Download the zip file "Base64 Encoder and Decoder 2012 NIVerified.zip"
- Open the VI "Base64 Fast Encode 2012 NIVerified.vi" or "Base64 Fase Decode 2012 NIVerified.vi"
- Enter text into string control
- Run the VI
**This document has been updated to meet the current required format for the NI Code Exchange.**
Marco Tedaldi, University of Zurich, CLAD
Example code from the Example Code Exchange in the NI Community is licensed with the MIT license.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
This is very nice! I tested performance against calling the .NET 4.0 classes System.Convert.To/FromBase64.
- Large string (10 MB) encode-decode x 5:
- FastBase64: 2380 msec
- .NET: 1910 msec
- Small string test suite encode-decode x 10000:
- FastBase64: 6905 msec
- .NET: 8922 msec
The .NET code is maybe a little faster, but the overhead of calling to those libraries from LabView makes Fast Base64 win most of the time. Fast Base64 does use more memory, but I suppose anyone base64 encoding a 150 MB file shouldn't do it in memory anyway.
Your use of lookup tables is interesting. I was reminded of something from Rob Pike's "Notes on Programming in C" ("Algorithms, or details of algorithms, can often be encoded compactly, efficiently and expressively as data".) Might want to link to drop link to web page with where they come on the diagram.
Under what license are you releasing this? That is necessary for many of us to use your code. I like to use the MIT license because it is very flexible.
-Rob
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hello Rob
Thank you for doing this performance test. I've only tested these VIs against each other.
About the license: I'm coming from the GNU-(GPL) world so this would be a logical choice for me. But I know that this license is somehow "restrictive".
I've just read the MIT License and I think it is short and sums up nicely what I think a software license should look like.
I'll add a mention of the license to the text above.
Best regards
Marco
Marco Tedaldi, University of Zurich, CLAD
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I got slightly better performance when I dropped off some of the parallelism especially for encoding small strings. I'm guessing it's because of the overhead of setting up the memory.
Here's my code. (I'm using subroutine priority and preallocate)
I've also been thinking about trying to implement Base128 using some of the non-ascii but still printable characters after Char 0x7F
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thank you for this contribution!
I'm happy to see that people do not just take the "fast" in the name for granted but conduct own tests. This helps everyone to get improved performance!
I can well imagine, that for small strings the paralellism is not the optimal solution (as you mentioned, the overhead to set up threads and stuff). I think, there is no perfect solution for every situation.
What size of strings are we talking about here? And was it in encoding or decoding or both cases?
Marco Tedaldi, University of Zurich, CLAD
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
And about the Lookup tables:
I did not find any examples of pre made tables so for so I wrote a small VI to produce those tables for me (took some iterations to get them all right because I'm not that good at bit-shifting stuff in my head) 
My Idea was not to create the fastest base64-encoder / decoder in the world. I think, there are others that have done this with more optimized tools.
My idea is to stay with pure G-Code, so it is portable to almost any version of labview on every platform.
If I wanted to make a REALLY fast one I would have looked at implementing it in FPGA. There, bit-shifting and stuff is really fast... which would be quite interesting to test...
Marco Tedaldi, University of Zurich, CLAD
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Here's my benchmarking
| Method | Encode 1 Million 4-8 byte strings (ms) | Decode 1 Million 4-8 byte strings (ms) |
| Serial (Subroutine) | 351 | 448 |
| Parallel | 16372 | 3576 |
| Parallel + Subroutine priority | n/a | 500 |
| Method | Encode 50 MB String (ms) | Decode 50 MB string (ms) |
| Serial (Subroutine) | 367 | 339 |
| Parallel | 294 | 718 |
| Parallel + Subroutine priority | n/a | 672 |
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thank you for those numbers! That's really interesting. Especially, since the arallel decode seems to be slower in every case!
I will definitely have to look into this.
Marco Tedaldi, University of Zurich, CLAD
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi,
I need to decode a Base32Hex string:
ASJJG1A4000008O31JPG003NH0036BHQ5O00000000000032 (This is an example how the string looks like)
into
hex string:
572738544000233CF30077880332E3A2E0000000062 (This is the resulting string of the example above)
I am very new to this kind of data manipulation so i am a little bit helpless myself.
Could the provided VI be modigied in order to convert base32hex to hex string?
Greets
Sacha Tholl
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Sacha
Those VIs could for sure be modified to accomondate it for base32. But it would take quite some effort.
The principle is the same:
Take a certains number of bytes, cut the up in smalle chunks (6 bits in base64, 5 bits in base 32) und use a table to substitute the values.
You can look up the tabe and the system on https://en.wikipedia.org/wiki/Base32
While In base64 the values of 3 bytes are stored in 4 bytes base32 uses 8 bytes to store the values of 5 bytes.
Those are really highly optimized VIs (especially the decoder part can be quite confusing). If you are new to this, it's for sure a good thing to learn. But it gan be a bit mind wrecking (I used quite some paper to jot down sketches on how I would have to manipulate the data to get the results I wanted).
When I started of (between 2002 and 2004) I used an example from the forums I think (which one I can't find anymore) and optimized on this. This example was very straight forward on how it was impleemented but slow.
I'd suggest you look trough a few of the base64 examples here (this is by far not the only one) and select one you can understand to change it for your needs.
Please don't forget to share your results here with the community.
Marco Tedaldi, University of Zurich, CLAD
