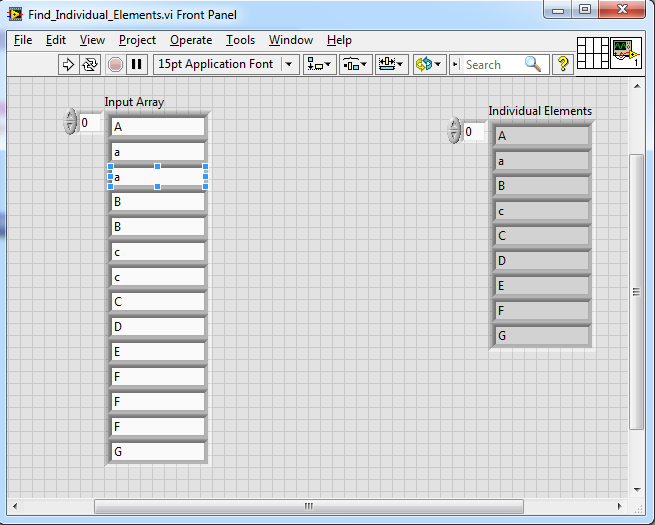
Finding unique elements in a string array
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Code and Documents
Attachment
This finds unique elements in a string array for repeat data.
National Instruments
Example code from the Example Code Exchange in the NI Community is licensed with the MIT license.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Building an array like that is very costly both in terms of memory and execution time. There is an OpenG function (if you do not already have the OpenG library I highly recommend it) called Remove Duplicates that does the job a bit quicker, but it too builds the output array one element at a time.
If speed and/or memory is important you should preinitialize the output array to the same size as the input array, and then just cut it down in size in one operation after filling it with unique elements from the start and onwards.
I've uploaded an example here. The example outputs a sorted list though, so if you do not want such a change in the order of the elements you will need to add another step to reorder the output, but you will still keep the gain in performance (assuming you do the reordering efficiently as well).
